해당 내용은 kocw 한양대학교 컴퓨터 네트워크 강의를 정리한 내용입니다.
강의 링크 - http://www.kocw.net/home/search/kemView.do?kemId=1169634&ar=relateCourse
지난시간에는 Transport계층에서의 reliable data transfer를 하기위한 원리와 이를 구현하기위한 메커니즘을 살펴보았습니다.
실제로 구현하기 위해선 pipeline 방식이 필요했고, 이를 구현하기 위한 2가지 접근인 go-back-N 방식과 selective repeat방식이 어떤것인지에 대해서 살펴보았습다.
이번시간에는 TCP header의 구조와 TCP header구조로 reliable data tranfer에 대해서 이야기 해 보겠습니다.
1. TCP Overview
- point to point
- TCP는 process와 process 한 쌍의 process끼리 통신을 추구한다.
- 여기서 더 자세히 이야기하면 한 쌍의 socket끼리의 통신을 책임집니다.
- reliable, in-order byte stream
- 데이터는 하나도 유실되지 않고, 순서대로 전송됩니다. byte stream단위로 전송됩니다.
- pipelined
- pipeline 방식으로 전송합니다. (window)
- send & receive buffer
- 실제로는 모두가 sender이자, receiever이기 때문에, sender window buffer, receiver window buffer를 각자 가지고 있습니다.
- full duplex data
- 모두가 sender이자, receiver이기 때문에 data가 양방향으로 전송됩니다.
- 그래서 내가 보낼 데이터는 sender buffer에 들어가 있고, 내가 받을 데이터는 receiver buffer에 들어가 있습니다.
- flow control
- receiver buffer의 남은 size만큼 sender가 데이터를 보내줍니다.
- congestion control
- 내부 Network가 처리할 수 있는 양 만큼 데이터를 보내줍니다.
2. TCP Header structure
먼저 TCP Header를 살펴보기 전에 각 계층의 전송단위부터 살펴보겠습니다.
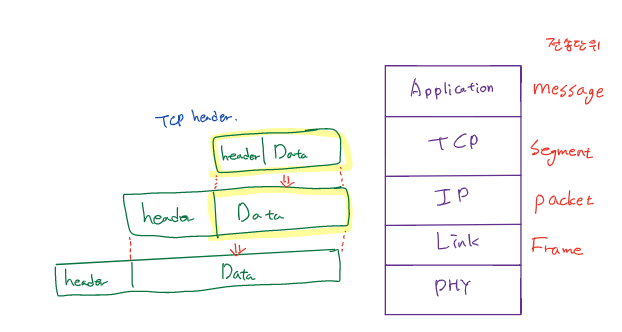
- Application의 전송단위 : message (HTTP request, response..... 실제 보낼 데이터들)
- TCP(transport)의 전송단위 : segment
- header와 data로 이루어져 있고, application에서 보낸 message가 data에 저장된다.
- IP(network)의 전송단위 : packet
- packet또한, header와 data로 이루어져 있고, data에는 segment의 header와 data가 data에 속한다.
- Link계층의 전송단위 : Frame
- 위와 같은 방식으로 header와 data로 나뉘어 있다.
(Header는 모두 overhead이기 때문에, 실제로는 매우 적은 데이터이다.)
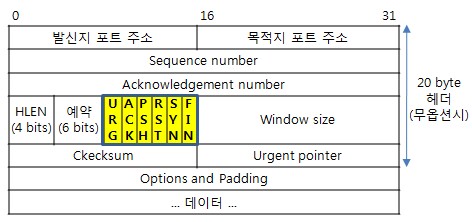
이미지 출처 : http://www.ktword.co.kr/abbr_view.php?m_temp1=2437
- 발신지 포트 주소(source port #) : 16bit, sender의 포트 번호를 저장한다.
- 목적지 포트 주소(dest port #) : 16bit, receiver의 포트 번호를 저장한다.
- 그래서 port번호는 0 ~ 65,000(대략) 사이 값으로 존재한다.
- Sequence number, ACK number
- HLEN : header length
- Check sum : error detection을 위한 필드
- Window size(Receiver window) : Receive buffer의 남은 size를 담은 값
- 그리고 1bit들의 flag들이 존재한다.
기본적으로 echo서버로 한번 data 전송이 어떻게 이루어 지는지 살펴보겠습니다.
(echo서버 : sender가 보낸 데이터 그대로 다시 sender에게 전송해주는 서버)
sender : A
receiver : B
A가 B에게 'C'라는 message를 보낸다고 합니다.
A는 B에게 sequence number : 42 / ACK : 79 / data : 'C' 이렇게 보내게 됩니다.
** sequence number 수는 보내는 데이터의 첫 번째 byte 번호입니다.
100개의 연속된 byte를 보내는데, sequence number가 42번이면 42번째 데이터를 보내는 것입니다.
만약에 40 ~ 49번까지의 데이터를 보낸다면 sequence number는 보내는 데이터의 첫 번째 byte번호인 40번이 됩니다.
(Seq # : 40)
TCP에서 ACK는 cummulative ACK 입니다.
ACK79이면 78번 까지는 잘 받았고, 79번 데이터를 기다린다는 뜻입니다.
아무튼 A로 부터 seq # : 42, ACK : 79, data : 'C'가 B에 도착했다면
B는 seq # : 79 / ACK : 43 / data : 'C'를 A에게 보냅니다.
아까 A로 부터 ACK : 79를 받았기 때문에 79번 데이터를 보내주고, 그래서 sequence number값이 79가 됩니다.
그리고 A로 부터 42번 데이터를 잘 받았기 때문에, ACK는 43으로 42번까지 잘 받았다고 A에게 알려줍니다.
만약에 "computer"라는 메시지를 보낸다면 (8byte)
A : seq # = 42 / ACK = 79 / data = "computer"가 되고,
B는 : seq # = 79 / ACK = 50 / data = "computer"로 전송합니다.
"computer" -> "c(42)o(43)m(44)p(45)....r(49)"입니다.
B가 보내는 seq #는 B가 만드는 것이고, 그 번호가 A가 보내는 ACK번호를 결정합니다.
만약에 B가 A에게 seq #가 40인 메시지를 1byte를 보내면, A의 ACK는 41이 됩니다.
그리고 A가 ACK로 79번을 보냈다면 78번까지는 잘 받았다는 뜻이기 때문에 B의 sequence 번호는 그 번호인 79가 됩니다.
3. Timeout
timeout value는 얼마만큼 setting 할 것인가? 에 대한 내용입니다. (pacekt loss에 대한 대처)
유실은 확실하게 하면서 timeout value는 작게 하는것이 목표입니다.
그래서 RTT라는 개념을 도입합니다.
- RTT : round trip time -> pacekt이 왕복하는데 걸리는 시간
timeout value를 RTT로 잡아보자.
그런데 실제 packet들은 모두 다 경로가 다르고, 같은 경로를 지나더라도 queueing delay가 항상 다르기 때문에 RTT값이 항상 달라집니다.
즉, 매번 RTT를 측정할 때 마다 값이 달라집니다. 그래서 대표값을 잡아야 하고, 그것이 바로 estimated RTT 입니다.
Estimated RTT : packet을 보낼 때 마다 RTT(simple rtt)를 측정하고 weight를 주어서 estimated RTT값을 수정합니다.
4. TCP reliable data transfer
TCP에서 제공하는 reliable data transfer에 대해서도 살펴보겠습니다.
- pipeline 방식을 사용한다.
- cumulative ACK이다. (ACK10 이면 9번까지 잘 받았고, 10번을 달라는 뜻이다.)
- 하나의 timer만을 사용한다. (Go-Back-N과 비슷하다.)
- 그러나 timer가 발동할 때 window 전제 재전송이 아닌, 문제가 된 packet만 전송한다 (selective repeat)
A와 B사이에 데이터를 전송한다고 가정하겠습니다.
TCP 재전송 시나리오
1) ACK가 loss가 되는 시나리오
A가 seq # : 92, 8 byte 데이터를 전송합니다.
B가 잘 받아서 ACK 100을 전송했는데 이 ACK가 loss가 되었습니다.
A의 timer가 발동되고, 다시 seq # : 92, 8 byte 데이터를 전송합니다.
그리고 B는 ACK 100을 재전송 합니다.
끝
2) ACK가 timeout 이후에 오는 시나리오
A가 seq # : 92, 8byte 데이터, seq # : 100, 20byte 데이터를 순서대로 보냅니다.
B가 위 두개의 데이터 모두 잘 받아서 ACK 100, ACK120를 순서대로 보냈는데, 두 ACK모두 늦게 A에게 도착해서 A의 timeout이 발생해 버렸습니다.
그래서 A는 다시 seq # : 92, 8byte 데이터를 전송하였고, B는 이를 잘 받았습니다. 그리고 B는 119번까지는 이미 받았기 때문에 ACK120을 재전송 합니다.
그러면 A는 119번까지 잘 받았다는 뜻이기 때문에, seq # : 120부터 전송을 이어나갑니다.
끝
3) ACK하나만 loss가 되는 시나리오
A가 2번과 똑같이 보냈는데, ACK100은 유실되었고, ACK120만 A에게 전송받았습니다.
하지만 ACK100이 없지만 ACK120은 119번까지는 잘 받았다는 뜻이기 때문에 ACK100이 없어도 119까지 buffer를 비웁니다.
실제 timeout은 상당히 긴 시간이기때문에, seq # : 92의 timeout까지 기다리는건 시간낭비라서 빠르게 buffer를 비웁니다.
끝
여기서 조금만 더 생각해 보면 timeout 되기전에 packet이 유실되었는지 알 수 있습니다.
1 ~ 100까지 1자씩 보내는 경우를 생각해 보겠습니다.
순서대로 1byte씩 보내는데, 10번이 유실된 경우
sender는 ACK1, ACK2, ACK3, ACK4..... ACK9까지 받고, 10번 packet이 유실되었기 때문에
ACK10, ACK10, ACK10, ACK10, ACK10.....으로 계속 ACK를 받습니다.
이럴때는 timer가 터지기 전에 10번 packet을 다시 보냅니다. (권고사항) 이를 fast retransmission이라고 합니다.
3 dup ACK10을 받을 때(총 4개의 같은 ACK를 받아야 한다.) fast retransmission하는것이 IEEE 권고사항입니다.
그래서 10을 다시 보내면 ACK80 or ACK100을 받고 계속 전송을 이어 나갈 수 있습니다.
'컴퓨터 네트워크' 카테고리의 다른 글
| (컴퓨터 네트워크) 5. Pipeline protocol (0) | 2020.05.16 |
|---|---|
| (컴퓨터 네트워크) 4. Reliable Data Transfer (0) | 2020.05.11 |
| (컴퓨터 네트워크) 3. Socket Programming (0) | 2020.04.27 |
| (컴퓨터 네트워크) 2. Application (0) | 2020.04.10 |
| (컴퓨터 네트워크) 1. Introduction (0) | 2020.04.08 |


